幅優先探索と深さ優先探索
この記事はアルゴリズム初級者~中級者に向けた頂点探索アルゴリズムの解説です。
下図のような辺と頂点からなるグラフについて、辺をたどって各頂点を探索する方法を考えます。ただし、スタート地点の頂点を0番目とします。
幅優先探索
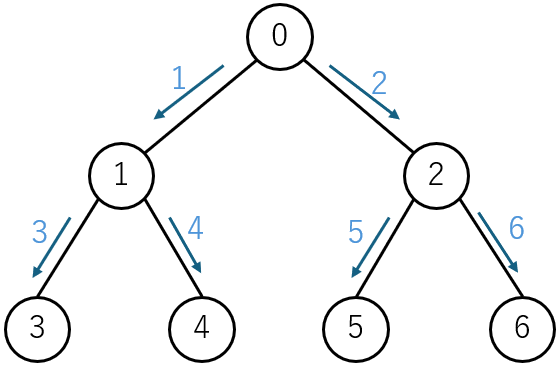
上図のように各頂点から出る辺を並列にたどります。ここではキューを使います。
キュー(deque)
リストと似た構造ですが、先頭と末尾の要素をO(1)で追加、取り出すことができます。その代わり、両端以外の要素の操作にはリストより遅くなります。
リストでは末尾の要素の操作はO(1)で出来ますが、先頭の要素の操作にはO(n)のコストがかかります。
探索
キューに頂点0が入っている状態から始めて、キューが空になるまで下の手順を繰り返します。
- キューの先頭にある頂点を取り出す。
- 取り出した頂点と辺でつながっている頂点を全てキューの末尾に追加する
深さ優先探索
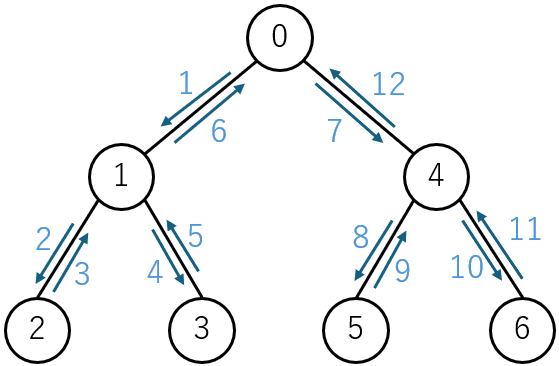
上図のように行き止まりまで探索し、行き止まりになったら分かれ道まで戻る、というのを繰り返します。ここでは再帰関数を使います。
再帰関数
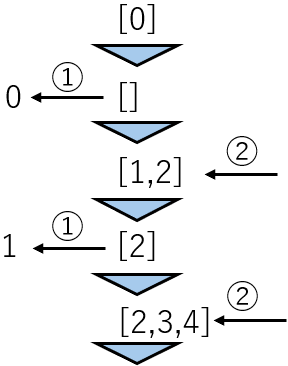
関数内で自身を呼び出す関数です。下の例ではfunc(i)内でfunc(i + 1)が呼び出され、func(i + 1)内でfunc(i + 2)が呼び出され、とストッパーが発動するまで続きます。
ここで、func(i)からfunc(i + 1)が呼び出される様子は上図の下向きの矢印、func(i + 1)の処理が終了した後func(i)に戻ってくる様子は上図の上向きの矢印で表されます。
def func(i):
# ストッパー
if i > 1000:
return
func(i + 1)
ただしPythonでは再帰の深さに制限がかけられており、デフォルトで1000となっています。競プロではほとんどの場合足りないので、上限を1000000に変更します。
実装例
「下の迷路はスタートからゴールまでたどり着けるのか」という問題を解いてみましょう。sはスタート、gはゴール、#は壁、.は道を表し、迷路の外周は壁に囲われているとします。また、上下左右に1マスずつ進むとします。
s.#..
..#..
.....
##.#.
....g
M = [['.','.','#','.','.'],
['.','.','#','.','.'],
['.','.','.','.','.'],
['#','#','.','#','.'],
['.','.','.','.','.']]
同じところをグルグル回っていてもゴールまでたどり着けないので、一度通った場所にはチェックを付けるようにします。
# 一度通った場所はTrueにする
visited = [[True,False,False,False,False],
[False,False,False,False,False],
[False,False,False,False,False],
[False,False,False,False,False],
[False,False,False,False,False]]
また、迷路内の座標について、M[i][j]を(i, j)と表します。
このとき、上移動は (i, j) → (i - 1, j) 、
下移動は (i, j) → (i + 1, j) 、
左移動は (i, j) → (i, j - 1) 、
右移動は (i, j) → (i, j + 1) となります。
幅優先探索での実装
# キューを作成
from collectons import deque
Q = deque([(0, 0)])
# Qが空になるまで続ける
while Q:
i, j = Q.popleft()
# ゴールにたどり着いたらYesと表示し、終了
if i == 4 and j == 4:
print('Yes')
exit()
# 上に移動
if i > 0 and not visited[i - 1][j] and M[i - 1][j] == '.':
visited[i - 1][j] = True
Q.append((i - 1, j))
# 下に移動
if i < 4 and not visited[i + 1][j] and M[i + 1][j] == '.':
visited[i + 1][j] = True
Q.append((i + 1, j))
# 左に移動
if j > 0 and not visited[i][j - 1] and M[i][j - 1] == '.':
visited[i][j - 1] = True
Q.append((i, j - 1))
# 右に移動
if j < 4 and not visited[i][j + 1] and M[i][j + 1] == '.':
visited[i][j + 1] = True
Q.append((i, j + 1))
# ゴールできなかったらNoと表示
print('No')
深さ優先探索での実装
# 再帰上限を変更
import sys
sys.setrecursionlimit(1000000)
def dfs(i, j):
global check
# ゴールにたどり着いたらYesと表示し、終了
if i == 4 and j == 4:
print('Yes')
exit()
# 上に移動
if i > 0 and not visited[i - 1][j] and M[i - 1][j] == '.':
visited[i - 1][j] = True
dfs(i - 1, j)
# 下に移動
if i < 4 and not visited[i + 1][j] and M[i + 1][j] == '.':
visited[i + 1][j] = True
dfs(i + 1, j)
# 左に移動
if j > 0 and not visited[i][j - 1] and M[i][j - 1] == '.':
visited[i][j - 1] = True
dfs(i, j - 1)
# 右に移動
if j < 4 and not visited[i][j + 1] and M[i][j + 1] == '.':
visited[i][j + 1] = True
dfs(i, j + 1)
dfs(0,0)
# ゴールできなかったらNoと表示
print('No')
使い分け
深さ優先探索は迷路のような問題の場合、遠回りする可能性があります。
一方、幅優先探索は多数の経路をまとめてキューで管理するためメモリを大量に消費します。
基本的には遠回りする可能性がある場合は幅優先探索、そうでない場合は深さ優先探索を使います。
幅優先探索の応用
01BFS
先ほどの迷路問題を少し変更します。
移動に0または1のコストがかかるとし、スタートからゴールへ行くための最小コストを考えます。0のマスに進むためのコストが0、1のマスに進むためのコストが1です。
s0#00
00#10
10101
##1#0
1001g
ここでは、コストが小さい経路を優先して探索します。
通常の幅優先探索では、進んだ先の情報を全てキューの末尾に追加していましたが、01BFSではコストが0の場合はキューの先頭へ、1の場合はキューの末尾へ追加します。
上記の例題で、上方向への移動を通常の幅優先探索と01BFSで比較してみましょう。
# 通常の幅優先探索
if i > 0 and not visited[i - 1][j] and M[i - 1][j] == '.':
visited[i - 1][j] = True
Q.append((i - 1, j))
# 01BFS
# 現在のコストの合計をcとする
if i > 0 and not visited[i - 1][j] and M[i - 1][j] != '#':
visited[i - 1][j] = True
if M[i - 1][j] == 0:
Q.appendleft((i - 1, j, c))
else:
Q.append((i - 1, j, c + 1))
現在のコストがcの時、キューには前半にコストcの経路が、後半にコストc + 1の経路が入っています。コストcの経路を全て探索し終えると、コストc + 1の経路を探索し始めます。
ダイクストラ法
移動コストが01に限らず、様々な数字をとる場合を考えます。
s4#83
02#26
15191
##2#0
1701g
01BFSと同様に現在のコストが小さい順に探索します。しかし、この場合dequeではキュー内の最小値が必ずしも先頭にあるとは限りません。そこで、優先度付きキューを導入します。
優先度付きキューとは、ヒープソートを利用して
- 要素をO(log(N))で追加する
- キュー内で優先度が最も高い要素をO(log(N))で取り出す
ことができるキューです。
Pythonではheapqをつかいます。これは、値が小さいほど優先度が高いとみなす優先度付きキューです。ソートを使うため、比べたいもの(今回はコスト)を先頭に置くようにしましょう。
上記の例題でdequeとheapqの使い方を比較してみましょう。
- キューの作成
# deque
from collections import deque
Q = deque([(0, 0)])
# heapq
# コストを先頭にする
import heapq
Q = [(0, 0, 0)]
heapq.heapfy(Q)
- 要素の取り出し
# deque
i, j = Q.popleft()
# heapq
c, i, j = heapq.heappop(Q)
- 要素の追加
# deque
Q.append((i - 1, j))
# heapq
heapq.heappush(Q, (c + M[i - 1][j], i - 1, j))
さらに、全ての要素を-1倍することでheapqで最大値を優先して取り出すことができます。